Intro
I mentioned I meant to use a database at some point for my logs and with R. Well, I will explain a (tiny) bit about that today.
But first, what data can I possibly put into my upcoming “NoSQL” database? Well, I now have lots of data. I’ll use the DNS records from my “Home Lab” server (that’s why I got it in the first place).
Today will be a bit of a mix between Containers, parsing logs, Functional Programming and contextual data for Domain names…
First: The data
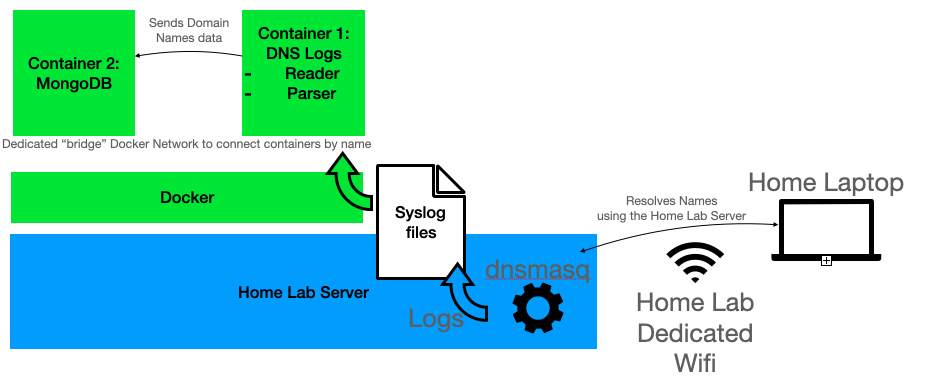
So I have DNS data, which comes from using my “Home Lab Server” as a Wifi AP, with a dnsmasq server running on it, and configured to log data (which goes to the /var/log/syslog file).
Not much to discuss here, although in the current setup, I create a copy of the syslog* files to a different directory which I’ll mount locally in my “rocker” (Docker Container for R, in this case one with RStudio for convenience as I’ll be working on that script later on).
DNS Logs treatment: Domain Age
One of the things, beyond reading a file and extracting a subset of lines (today we’ll focus on DNS Queries specifically, so that’s what I’ll look for, using regular expressions)… One of the things I want to do is to add context to the gathered data. We had domain names, requesting IP and a timestamp.
What I am interested in right now is knowing the “age” of the domains requested by my devices. This is a common metric related to security, as this might help us classify a domain as potentially malicious. It is generally accepted that VERY NEW domains are… Well, suspicious.
That metric, along with others, might help create a classifier of some sort in the future, using ML, but that’s beyond today’s objective.
So how do we know the “age” of a domain?
Well, a domain name is bought on a certain date. That’s what we’ll be looking for, the registration date for a domain name. Not TLDs (mind you) nor (necessarily) hosts, but rather “domains”, are of interest here.
A simplification to go about this is to extract from the FQDN the TLD and “second level” of the name. (Arguably, not the best way to go, as for instance for domains like “google.co.uk” I’d be looking for “co.uk”, which, well, isn’t what we want).
Nevermind that limitation, as I have made a special effort today to go “functional” about the code. That’s because I want to see how much it helps me; but a first by-product is that I am confident I will be able to solve the about issue without breaking everything else rather easily at some later point.
Now for those who are following, the way to find out about the creation/registration date of a domain is to use a “whois” tool. As my containers could run a standard Linux, I could use something along the lines of:
system("whois google.com")
But I’m not too fond of calling the OS tools if that can be avoided. Thankfully, there is, as is often the case, a library to do just that kind of things:
library(Rwhois)
temp <- whois_query("google.com")
Works (so far) just about fair enough for my needs. Among the output of that command, a key called “Creation Date” points to a value, which, indeed, is a date
temp[temp$key == "Creation Date","val"]
Now that date, in my tests, is not always in one format, so that’s something I’ll have to work on later on. But for now, let’s just say, fair enough.
Adding a Database to the mix: MongoDB
Well, at this point I have a bunch of domain names along with their “creation date” (if all went well).
I can simply save that in a CSV. (I actually do: Whois requests can take a few seconds to come back with an answer, and with hundreds of domains for which to get the creation date, it took more time than I cared for, so I implemented a rudimentary “cache” file to NOT request several times the whois info for the same domain names.)
But what might be better is to be able to save this “cache” in a database of its own. I initially thought about a SQLite container and a very basic database schema for all the data related to my DNS queries… But what would be the fun in that?
No no, this time around, I need to experiment some more. While thinking about how I would go about it (over the past few days), and looking for something completely different (streaming input data into a Shiny App), I came across this presentation, which made my day (and gave me material to work with for future labs :)).
Which is why I chose MongoDB as my new “No SQL” database backend.
But then again, I want to keep things in order. So I went on and looked for the simplest possible way to test MongoDB, see if it made sense for my use case at all.
Once again, Docker to the rescue.
A new Docker Network
But wait, I mentioned in the past that for two containers to “talk” to each other, either you gather the IP of each in run-time, or you need to create a dedicated “Docker network”. Well, let’s do just that:
sudo docker network create --driver=bridge --subnet=172.28.0.0/16 --ip-range=172.28.5.0/24 --gateway=172.28.5.254 r_analysis_br0
Then I can run my containers and see if they can “talk” with each other, by “attaching them” to the new network:
sudo docker run --name mongo1 --network=r_analysis_br0 -p 1235:8081 -v `pwd`/mongo_1/data/:/data/db -d mongo
I do that so that I can call the container by its name (mongo1), provided I am calling from another container (on the same host, because of the “bridge” driver used) also attached to the same network, like so:
sudo docker run --name rocker1 --network=r_analysis_br0 -p 8787:8787 -v `pwd`/Rcode/:/mnt/R/ -e PASSWORD=anypasswilldo rocker_base001
Testing connectivity
Sure enough, I will now be able to connect to the mongo1 container, on its default MongoDB port (8081), from another container (rocker1 in this case).
Note: I created a Dockerfile for rocker1 and built it from there, as I needed to add some packages added to it. But it is essentially rocker/rstudio, with the tidyverse meta-package, Rwhois (see above) and mongolite (for the next bit).
And to actually test that, I can now see if I can save my domain names along with their creation date (where available, that is). Long story short, the last command here returns TRUE, which means all the rows of my data.frame where indeed loaded into the MongoDB collection “domain_dates” in the “DNS” database:
library(mongolite) # Default, NOT SECURE: m <- mongo(collection = "domains_date", db = "DNS", url = "mongodb://mongo1") print(m) m$insert(domain_created_date) # Everything went OK? m$count() == nrow(domain_created_date)
Working on the R Kung-Fu
The MongoDB setup itself didn’t take much of an effort, it was pretty straightforward (although it is too simplistic and very probably very INSECURE… I’ll look into that later on).
But what took me some more time was to work on the R Kung-Fu itself.
The R code for today, as usual, on my GitHub Account.
I looked further into the “Functional Programming” paradigm these past few days, and although I expected it to possibly make code shorter (apparently not so), I still worked in that general direction when reading logs and parsing the DNS queries today. And that took some time, and it’s far from “purely functional” code, but I believe I made some strides in the right direction.
Some nice references about this (Functional Programming, though through “Clojure”) here.
But what’s more important: It does help. Not only does it work. The ability to pinpoint to a very specific function and test and debug just that, knowing that when it works (after breaking it, that is) all the rest of the code will still behave as expected, is quite liberating.
I had an issue with reading the year of the syslog files, whereby I didn’t account for the fact that files rotated at midnight would contain data from the day before, while the timestamp of the file, which I use, is from “today”. That was an issue for logs of December the 31st, as you might expect. I found out while plotting the data (queries per day) and seeing the lines all along 2021 for 5 days of data (once again, visualizing data IS IMPORTANT). But it took me 1 minute to fix it, as there was a function meant only to add the year from the files into the logs.
Another thing about Functional Programming and returning functions as objects (see past post about functional programming intro), was that in that case I decided to go for limited environment scope for one of the functions. Let me explain:
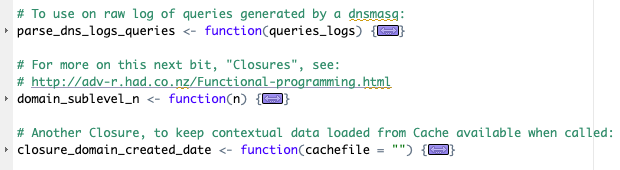
I created a Closure which will first create a dataframe from a file to then create a function (object). That dataframe will only be available to the “child” function (and hopefully I won’t need it elsewhere, otherwise this was a stupid idea).
That’s cool because my “child” function now can be called knowing it has some contextual data available to it, without having to read it all again upon each call (which was great because I wanted to “lapply” the hell out of it, precisely).

The last line in the screenshot is actually the one that will be used to create the “child” function (there is more to it below that end of screenshot, but it wouldn’t help here), and it will be able to see “cache_data”, which is not accessible for the rest of the script.
# A file in CSV format with domain,date_create columns: domain_created_date_context_data_file <- "/mnt/R/domains_created.csv" get_domain_created_date <- closure_domain_created_date(domain_created_date_context_data_file) # OK now load date of creation for each domain observed in the DNS Queries (Level 2): domain_created_date$created_date <- sapply(domain_created_date$domain, get_domain_created_date)
Now you’re right: I could simply have read the “cachefile” outside of the function and used it as a global variable. That would have worked just about the same indeed.
But this seems cleaner: I only create the cache data for the scope of its use. Then I create a function SPECIFICALLY for it. On the downside, if the cache data grows too big, it is harder to get rid of it as it is not “directly” accessible. I’ll look into that some day, it might be important in the future (who knows).
I also worked a bit more with tryCatch, as Rwhois misbehaved in some fringe cases (whois_query(“google.es”) won’t work the way I want still now – I’ll have to look into that). Once again, I know exactly where to look in my code, thanks to the many functions defined, and once I fix it, the rest of the code will just benefit from it.
Another advantage, for RStudio users, is the ability to “compress” the function, so that the function code is hidden from your sight, making the rest of the code all the more readable.
Conclusions
Following some “Functional Programming” best practices, with a new MongoDB backend launched in a new container on my Home Lab Server (I’ll talk about making all things Docker persistent across reboot in a later post), and actually reading in “real world” DNS queries data and adding relevant context to them.
Not bad for a (long) afternoon of (spare time) dedication.
Future efforts might include:
- making things work as streams (so that I don’t load from scratch every time, and instead I load data as it shows up maybe)
- Putting all the DNS data parsing and wrangling things in a Plumber container (without RStudio, lighter version)
- Mixing in the Replies data (with all the IPs and CNAMES and stuff), and maybe the countries through our past exercise of GeoIP
- Maybe some Machine Learning would be good (maybe some clustering to see if there is something to see, some structure, etc…). That might then in turn include:
- Features Synthesis (i.e. we have dates, we could get frequencies of domain calls per hour of the day, maybe lengths of domain names, maybe frequencies for countries associated to domain names, the domain age that we already have, and maybe crazy ideas like frequencies of letters in the domain names (domains with many x & y’s might get clustered differently from those with more usual letters?)).
- Note: Clustering is meant for that, NOT for classification…
- Then Features reduction through PCA, using best practices where applicable (Z-Score…)
- But we have the “clients” (Mac, mobile phone, Windows Laptop…) as potential categories for a supervised classifier, maybe using TF-IDF on domains names requested per device, see if we are able to train a Random Forest or a simple NNet to classify the type of the requesting machine based on what domains it asks about (doesn’t sound too crazy upfront…)
- Maybe we can mix the results from the clustering and some supervised algorithm to pinpoint unwanted queries (that would be ideal, but I won’t hold my breath on this one)
- Putting it all in different containers and getting things together into a nice “DNS logs Monitoring Dashboard” in Shiny
Plenty can still be done with the simple logs of DNS requests… Not to mention that we could correlate those with the Netflow data we are also collecting on the server…
Plenty can be done, but I only have so much spare time. (Actually I have more obligations I’ll need to attend to, so I might not be able to publish new stuff for a few weeks – sorry for that :S).
References
https://hub.docker.com/r/rocker/rstudio
https://stat.ethz.ch/R-manual/R-devel/library/base/html/system.html
https://jeroen.github.io/mongo-slides/#1 (Great stuff in there!)
https://cran.r-project.org/web/packages/Rwhois/Rwhois.pdf
https://docs.docker.com/engine/reference/commandline/network_create/
https://jeroen.github.io/mongolite/