New CPUs
Yesterday morning I received my new “home server”, let’s call it “home server 2”. It’s a miniPC. But it still has… 16 threads!
I skipped lunch yesterday, but about an hour later (it was fully new, I had to configure everything from scratch), it also sported a WSL2-based Ubuntu 22.04+Docker Desktop, on top of (yes, I know, it’s not great) Windows 11. At some point in the future, I’ll reinstall, for sure – so no Windows, no WSL2, just “plain” Ubuntu+Docker. But for this early exercise, this is good enough.
Also, it’s a rather “cheap” miniPC (well, depends on the budget of each one of course, I am lucky I could buy it in the first place, I know), as the goal is not so much to actually do MUCH more processing, but simply to reduce processing times and prepare a “product”, showing off I learnt something in the HPC courses (I did, at least some theory behind the practices I already used), here in the form of orchestrated containers.
Why bother using Docker?
Because I can make a container and test it all from the Mac, prepare some code to “register workers”, and then get my Mac’s RStudio to act as an orchestrator that requests processing to the “workers”, containers that I could later in theory distribute rather *easily to new compute power* (i.e. more CPUs) provided I can just run Docker containers on there (which is most cases).
This is actually already a (MacBook + Ubuntu) setup, so already mixed up a bit… Which is one nice thing about Docker, for sure!
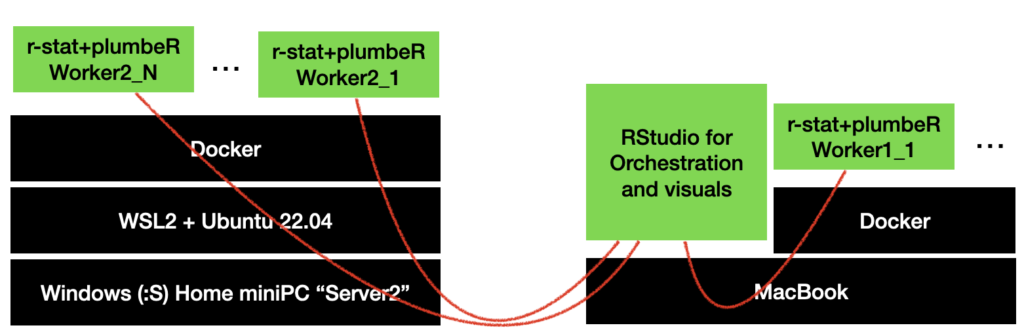
This above is a simplified layout of the “final” setup for this upcoming weekend – but it already “worked” (yesterday).
However, because I already parallelize at the code level, I do NOT really need to setup MORE containers per machine, as long as I give as many threads as possible to each one container. In other words, I’m probably actually better off with FEWEST possible containers, maximizing computation power available PER container… (But if I had MORE machines, then yes, indeed…)
That’s an excuse right there for me not needing to dive into Docker Compose, Kubernetes and other orchestrators, yes. Maybe I should dig into these topics some more (now that I have a machine to play with that is rather capable of distributed processing…)
Moreover, no, there is no actual need to setup any container for a worker on the Mac. I could use the RStudio R session to run simulations directly, too. But that would “break the concept” I guess. It would be slightly faster (for sure!) but less elegant in a way…
And also, there was no need to use containers at all, I could just use R from the Windows/Linux machine… Yes, true. That said, the “packaging” side of having containers is nice, as it makes it easily reproduced on more machines (again, provided Docker is available).
So no, Docker was NOT needed, but it gives a “DevOps” smell to it all, you could say. It’s just very convenient to deploy on more machines.
The missing piece
So on my Mac, it all works the way I expect.
From the new “miniPC”, I can also already serve (note for config Windows firewall to allow incoming connections from my private Wifi, obviously) a basic container, which I create from a (simplistic for now) Dockerfile that kicks up an r-stat basic container, loads plumbeR and a couple dependencies, and then creates a “plumber server” (not actually using the rocker/plumber image this time around, because well, I wanted to keep it as clean and lean as possible).
Still, essentially I just setup the same thing as I already did here (quite) some time ago. But now with more threads available to play with.
What’s missing really now is: The “new” miniPC has twice – compared to the original “home server” – the CPU Cores (8 instead of 4) but ALSO twice the thread count per core (2, that wasn’t hard :D), so a total of 16 threads. (It’s an AMD Ryzen7, much cheaper than equivalent (in thread counts) Intel, from what I could see when I was searching for a cheap but good enough solution – And I’m not getting paid for any of it, so this is not an Ad for AMD, just an observation to clarify the setup.)
Now I expect R to “see” 16 cores to work with.
I hope it won’t see only 8 (number of cores). It wouldn’t make sense at all – I don’t expect that will happen, and it would be a real painful finding -, but I haven’t yet *checked* that from an R script – that was stupid, I know, it could have been done in 5′ – , only from the WSL2 Linux perspective…
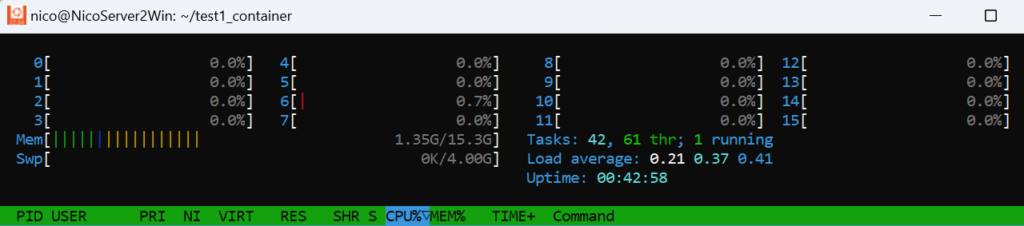
That’s hence left for the weekend, when I refactor everything (it’s a bit of work in fact, I’m not sure the weekend will be enough to do it “right”, hopefully it will suffice to “get it to work”, as I have other plans too…).
A note from the above… The Ubuntu (WSL2) was seeing… 15.3GB of RAM. That’s weird, I would have sworn the miniPC in fact had 32GB… Maybe something with limited bits for the OS? I’ll have to check. No biggy though, RAM memory is not the issue in this project, all I need is more CPUs.
(Actually… I also still have of course my original “home server”, still acting as firewall and my “personal Wifi” AP, and it also sports Docker, as I have already used it in similar setups in the past… I could distribute a little bit of work to it. It’s just… Much less powerful and not meant for high loads, passive cooling and all, so… Still, maybe I can spare one core-thread on there, just for the fun of it, for a quick test :D)
Conclusion
Well if I do this right, I will have moved my small personal R/C++ infection simulation project from a single machine (albeit nice Air M1 with multi-core processing) to a container-based somewhat-orchestrated distributed setup.
I’m just one step away (and quite a few million bucks) from a “Super Computer” setup :D:D:D
This is much like you would do a “data processing product”, if you will, as I would “serve” processing power from API interfaces, to run some code of my own.
This is actually probably the way I would do it in a real work setting if I had to (I’m an enthusiast, not a programmer), because then you (here you are the “customer”) don’t care what language I use (using R is often *not* widely accepted out there in the Corporate world for Production environments, I am well aware and I understand and accept that and I don’t even want to discuss it anymore, it’s SO pointless).
As if I can choose to use R or any other set of languages and products, but keep it “transparent” for you, “containerized”, “packaged” basically, for simple projects like that – i.e. providing containers – we’re all happy! (Actually, theoretically, more complex projects too, but that’s a very different story :D)
Also, it then of course is scalable (horizontally, anyway), which is cool (and the whole goal of this part of the exercise, in fact), so for certain workloads, this is an obvious benefit. I mean, imagine a thousand CPUs… Or a million – well no, maybe not a million (why would I ever think about that? this is just a personal project and scaling was never a critical part of it :D).
Sure, yes, it’s not a “serverless” solution, some will say. I know. I don’t really care, I’ll be happy if everything works with my proposed setup. (Maybe in the future, who knows? I definitely don’t plan to do this here, I need to go back to the simulations themselves at some point. (yes, that last bit is just a bad excuse, I still have plenty of time :D))