Confirmed expected amount of processing units
Quick post to clarify that yes, I have up to 16 available threads for my R container(s) in the new miniPC.
And the containers work the same (that was expected) regardless where I run them.
Here a screenshot for situation as viewed from my Mac, with 3 containers running locally and assigned each 2 Cores (8*.25), plus one container running from the miniPC (internal wifi network, yes, I know, I should work on the TLS and authentication and all that, but that’s all way beyond the point for my short term objectives).
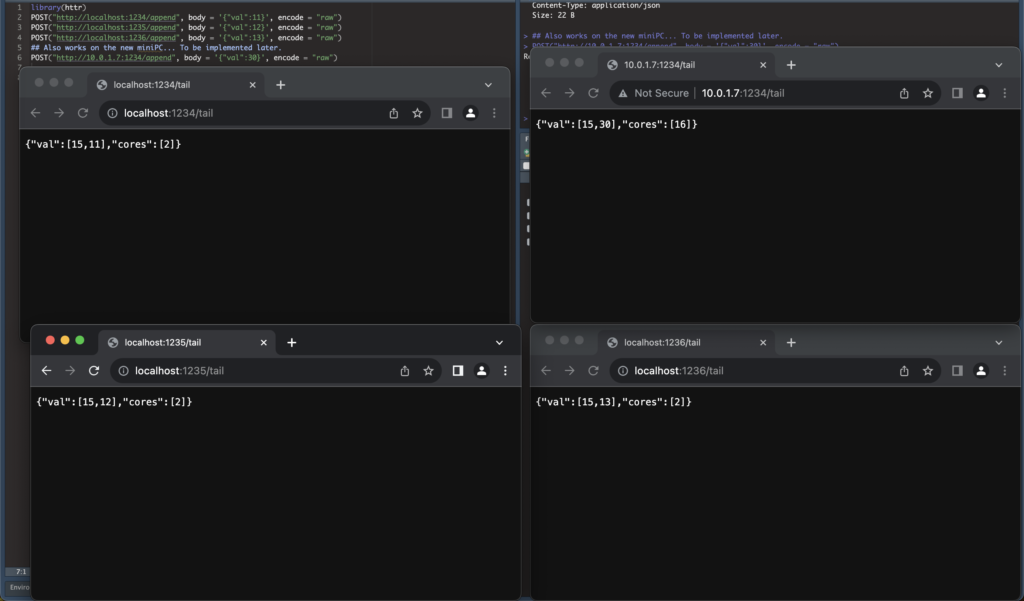
So workload “distribution” capacity is confirmed, and setup will work… But right now it does… Well, nothing much.
EDIT
Actually, I can’t seem to be able to restrict actual CPU count found by R’s detectCores() function. It would appear this is a “feature” of VMs, but not containers, i.e. for some reason whatever I do, htop in the container sees all available CPU Cores as shown to Docker. However, if running the container with the –cpuset-cpus and a list of CPUs, the container will see the correct number of CPUs USING nproc, but NOT using htop NOR with the aforementioned R function.
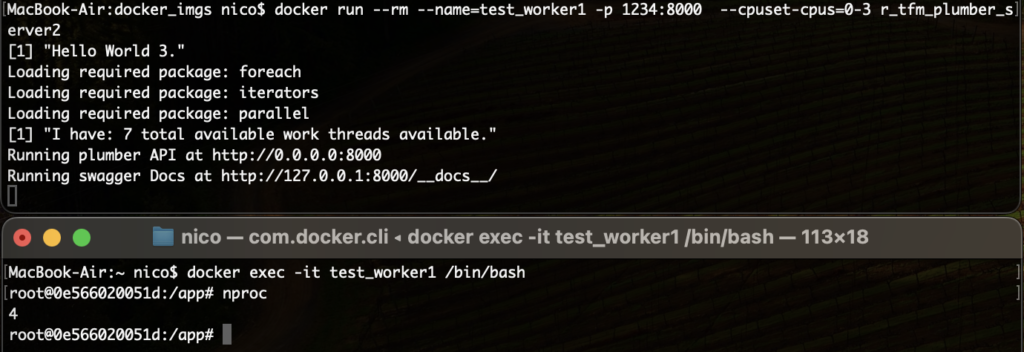
This calls for some consideration: I don’t want my containers to use ALL possible computing power. I can limit that by limiting available CPUs to the Docker engine altogether (easy in Mac with Docker Desktop, a bit messier in Windows…).
Or maybe I need to use the –cpuset-cpus runtime option ALONGSIDE a system call from within R to find out exactly how many cores I can actually use, and then use just that for registerDoParallel()… Messy, but more flexible.
Or I can limit in my R code, using say detectCores()-2, and ASSUME that I will NOT compete on the same machine with other containers… Simpler (and easy in my use-case), but not real-world compatible!
That was a bit unexpected 🙁 But OK, we will get around that.
Still dumb workers
I’m working on the refactoring of the code, I have indeed separated already “one configuration simulation run” from the rest of the code into a function: It will run one full GA optimization of a given SIS simulation from a given graph, a given budget and base Beta (say), some more parameters (population parameters mostly).
So I will next have to encapsulate such parameters as JSON, pass them as POST request to one or more workers (one config per worker, otherwise…).
Then obviously some more code to try and distribute the load a bit intelligently, so that I don’t have workers doing nothing for too long while others are very busy. So probably a simple loop, and a couple of functions to test availability of results, should do the trick. (There will be fragmentation and it won’t be optimum, sure, but it will still “multiply” the processing capacity, if not perfectly with the number of available processing units. That’s quite acceptable.)
And I should then be about ready to go back to the “actual work”.