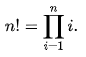
This time I’ll try to explain why the “Kaizen-R blog” even exists, through an example.
Improving through deliberate practice
This was THE idea, before the idea of the blog. This blog is only a consequence, really.
So this time, I focused on the deliberate practice, and I will only summarise it here, then reference you to the code itself.
The exercise is as follows:
- You can program in R.
- You can program better (in terms of style) in R.
- You can program OK and make sure you consider other things (tests, comments…)
- You can program “like a programmer”, using good algorithms (and still end up with very nice code but really bad execution times and/or memory usage).
- You can also program using R more native capacities, where applicable.
- You can even focus on execution speed, even compiling C++ code instead of using R.
- …
You can then consider all of the above and choose which way to go.
Different versions of the same thing
I created my own 6 “versions” of the “factorial” mathematical function. They are all presented in an R script I published here:
https://github.com/kaizen-R/R/blob/master/Sample/demos/kaizen_concepts_factorial_demo.R
First, have a look to the code referenced above. Now:
- As a beginner, not a computer engineer even, you would imagine someone could do something similar to the V1.
# Bad but functional
own_factorial_v1 <- function (x) {
i=1
while (x > 0) {
i = i * x; x=x- 1;
}
return(i)
}
- When you start with R directly, but still are a beginner, you could easily end up with V2.
- If you had experience with programming, and learnt about recursion, you probably would think about V3.
own_factorial_v3 <- function(x = 0) {
if(x == 0) return(1)
x * own_factorial_v3(x-1)
}
- V4 is about taking advantage of R and thinking of native R approaches (supposing you don’t know about the factorial() function before hand, and don’t remember to look for it…)
own_factorial_v4 <- function(x = 0) {
ifelse(x > 0, prod(1:x), 1)
}
- V5 is almost like V4, simply considering more tests.
- vCPP is to demo speed differences between compiled and interpreted code, really.
At the end of the day, I guess through deliberate practice, I aim at programming always considering “V5 and above” (see comments in the code below the V5 example, as I could have gone for V6, V7…).
Also, I include in the demo speed tests and unit-testing, to show how I want to be doing things onwards (for real-world code, not for demo/educational purposes). As always there is more to it (one could/should profile code and then only decide where to improve speed, for instance).
Conclusions
I guess there is no such thing as “perfect code”.
- For instance the recursive approach (V3) for the factorial calculation is (to me, the way I was taught about 20 years ago) very elegant and readable. But it turns out to be very slow with the R interpreter.
- V2 works and is what I would have done maybe 3 years ago.
- V4 is “R-like”, fast and elegant (one line!), but conceptually does only limited testing and in the real world, if it were a different function, might not be ready for security tests (e.g. SQLi and the likes…).
- V5 is a compromise (and only an example to show a concept): Conscious of weird use-cases (i.e. good for security/stability/integrity…), R-like (takes advantage of R capacity), and although it still can be improved, it is readable. It is documented, it comes with a comprehensive set of tests…
- The native function of course is great as it is the fastest and mathematically accepts real numbers (I haven’t checked if it works with complex numbers). And it looks cleaner too.
So maybe one conclusion comes to mind here:
Should I prefer using already existing packages where available? (I know, this goes a bit against a past entry where I discussed the risk of using third party libraries… But then again, I did say that there are trade-offs there too, security-wise…).
Using libraries can make you code faster and cleaner. Using the right library can have an impact too (choosing fread over read.csv maybe?).
But if you write your own code, which way is the good way to do it?
The more I work on “improving my programming skills in R”, the more I come to the conclusion that it’s all about trade-offs. These things I didn’t even think about in the past. Now I feel there is no “right” answer.
Maybe programming is art as much as it is science?
References:
https://github.com/kaizen-R/R/edit/master/Sample/demos/kaizen_concepts_factorial_demo.R
https://csgillespie.github.io/efficientR/introduction.html#prerequisites
http://r-pkgs.had.co.nz/tests.html#test-workflow
https://www.rdocumentation.org/packages/data.table/versions/1.12.8/topics/fread