Intro
I’ve mentioned a couple of times in the past the words “Shiny” and “Dashboard”. I think it’s high time we demo it and some of its capacities.
Disclaimer: One could use Excel to the what’s detailed here. But this Blog is about R programming mostly, so… We won’t be doing that today.
So I’ve created a dataset and we’re going to go through a bit of “voyage” into some of the RStudio’s Shiny tricks.
The data
In this case, I choose the concept of risk as the base concept. Risks are used both in IT Security & Project Management (albeit slightly differently). As I’ve discussed mostly Security lately, I’m moving to Project Management for this exercise.
Now in Project Management, one needs to keep track of potential risks affecting the costs, scope & timely delivery of a project (or set of projects).
A few things more about our dataset for today:
- Risks should be considered at the very beginning of a project (or, even better, before). But they tend to appear along the way too. So this is an evolving picture: Risks are identified on certain dates.
- Also, one can manage different projects. Keeping track of risks along all of them could be cumbersome, so I figure, let’s keep track of all risks for all projects in one place.
- Obviously, Risks have an associated Probability (of materializing) and Impact (how bad would it be if that thing happened). This is by definition of Risk. I choose the equivalent of “Low”, “Medium” & “High” for both magnitudes, but already encoded into numbers 1, 2, 3, respectively.
- Some are closed (hopefully) on another date, either because they materialized (they then become more a problem than a risk), or because the team managed them and mitigated their impact in some way (usually, through: avoidance, acceptance, transfer (think “insurance”) or mitigation)
- And some other things (a risk id maybe, risk name, risk description, mitigation description, etc.)
I created, for the goals of today’s exercise, just such a list of risks. You can find it here (it’s an Excel-exported CSV, using a semicolon as a separator, because I used european numbers, and the comma is used for our decimal numbers… This is a “feature” of Excel upon export to CSV around here… Anyway). If you want to follow along, just copy the content of the file into a notepad of some sort, and save it with the “.csv” extension.
Let’s move on.
The visualization (part 1)
Now to the good part. We have risks in a table. Our goal is to make the table more useful “at a glance”.
So the first thing that comes to mind, is to visualize the risks’ Impact & Probability, over two axis (x & y), which is rather easy UPFRONT, but one comes to realize, two risks with the same probability and impact would overlap… So how many are there for [2, 2]?
Two things then: We add noise to the numbers, just enough so that the don’t overlap exactly. And we make our point on the graph slightly transparent (option “alpha” of GGPlot’s geom_point()). Let’s say we’ve made it so that “demo_rr” is an object (a data.table in this case) containing the data in our CSV:
demo_rr[, Probability := sapply(Probability, jitter, 2)] demo_rr[, Impact := sapply(Impact, jitter, 2)] demo_plot <- ggplot(demo_rr, aes(x = Probability, y = Impact, colour = Risk)) demo_plot <- demo_plot + geom_point(alpha = 0.3, size = 5) demo_plot <- demo_plot + xlim(0.5, 3.5) + ylim(0.5, 3.5) demo_plot <- demo_plot + scale_color_gradient(low="green", high="red") demo_plot

OK. That’s a start.
On to the Shiny part
RStudio’s Shiny has proven invaluable to make my scripts more accessible to others in the past.
We’ve seen in a former post an interactive GGPlot, using Plotly. But that was somewhat limiting, as it assumed a user would go on and use RStudio’s interface.
With Shiny, one can make “Web applications” to be used by others. I’ve never used “Shiny Server”, so that’ll make for a future post, but in the meantime, Shiny still makes things rather easy to visualize & interact with a given dataset (even for myself), particularly when one uses a script often but doesn’t want to interact that much with the code every time.
A Shiny App has two main parts: A “UI” section, and a “SERVER” section.
- The UI section is all about what is shown, it’s kind of the HTML part of the traditional web page.
- The SERVER section is more about manipulating WHAT is shown (you can think about the Javascript code of a traditional web page, to keep with the example).
ui <- fluidPage(
fluidRow(h4("Shiny Interactive Example 1")),
selectInput("inSelect", "Select input",
c("Item A", "Item B", "Item C")),
textOutput("info")
)
server <- function(input, output, session) {
output$info <- renderText( paste("Selected Option:", input$inSelect) )
}
shinyApp(ui = ui, server = server)
Next up:
Instead of having the user input the path of the file to read the data from in the script, let’s make it a bit easier: Provided the user already has a file in the right format, let’s give him a button to select that file (a “Read file” button).
fileInput("risk_register_table", "Choose CSV File",
accept = c("text/csv", "text/comma-separated-values,text/plain", ".csv")),
checkboxInput("header", "Header", TRUE))
Now the code above is just a small part of the Shiny chunk of the final code. It would go in the UI part, and to make things simple, an object called “risk_register_table” in the example above is created to point to a temporary file to be used later. (We’ll get there.)
It gets tricky
One of the best tricks I’ve learnt about Shiny is the pair “reactiveVal()” + “observeEvent()” functions.
What it does is more or less as follows:
We separate the dataset manipulation from the generating of the outputs in the SERVER section of the code:
Say for example that you show your complete table at the beginning. But then you want to filter it in three different plots or graphs. You can go two ways:
- Read the filter input’s value in each of the plots generation code chunks, and adapt your code in each of the 3 sections,
- Or read it once, adapt the dataset, and then use the adapted dataset in all three code portions that generate each graph.
At first it is a bit confusing, but after a while, it helps a lot, as you work on generating your graphs only once, knowing the dataset will be pre-filtered in the way you want.
So what you do is you create a kind of function object to keep track of which filters are currently in use; you initialize your function to a default value with “reactiveVal()”, passing as argument the initial value you wish to begin with. Say you initialize a dataframe as follows:
my_dataframe <- reactiveVal(NULL)
Then you OBSERVE EVENTS, as the name says, with the “observeEvent()” function. What you do is you essentially monitor one of the “input” values, say “input$buttonPushed”. Whenever a user changes that input (selects a different value from a drop-down list or clicks on a button), the “observeEvent()” function, in the SERVER section of the code, will intercept that change. It will then go on and execute whatever code you have to update the dataset you work with.
It is important to finish your observeEvent() with something that updates the object you created with “reactiveVal()” earlier. What you do is set a new value for the “my_dataframe()” functional object. For example:
observeEvent(input$buttonPushed, {
my_dataframe(data.frame(variable1 = c(1,2), variable2 = c("A", "B"))
}
What’s neat about it is that in the rest of your SERVER section of code, you can then call whatever is in the my_dataframe() functional object (notice the “()” in the object, to distinguish from a more traditional object, reminding of a function object).
I won’t be putting all the code here for this, it is all available on my GitHub account, as usual.
What’s important is: You can update data to be used for several outputs at once reacting to an input event.
Another trick: it quickly becomes complicated when you allow your user to use MULTIPLE filters. What I usually do then is provide the different filtering options, and I only react WHEN the user CLICKS on an “Apply Filters” button. I then load the original dataset, and apply all the filters at once in my “observeEvent()” function. That way I can choose which filter to apply first, second, etc.
Updating the INPUT options on the fly
We also mentioned that our risks list covers more than one project. So it would be nice to be able to visualize only the risks for one of the projects instead of all risks at once.
We’ve seen how to create a “Select Input” box earlier, in the UI Section:
selectInput("inSelect", "Select input", c("Item A", "Item B", "Item C"))
But how to update the options available?
We can use the update of session-related input objects. This requires that your “server” section accept a session object as parameter:
server <- function(input, output, session) { ... }
I usually don’t use this much, and so I tend to forget to add the session variable in the function definition, but it’s a useful thing to have there.
You can now use that object to point to your input variables.
So say I have a select box as shown earlier in the UI section:
fileInput("risk_register_table", "Choose CSV File",
accept = c("text/csv", "text/comma-separated-values,text/plain", ".csv")),
checkboxInput("header", "Header", TRUE))
In the SERVER section, I can then use the updateSelectInput as follows:
updateSelectInput(session,
"project_filter",
label = "Project:",
choices = c("All", sort(unique(demo_rr$Project_Name))),
selected = "All")
Now as I observe another input variable for when the user has uploaded the CSV, I can, in the corresponding “observeEvent()” portion, call the updateSelectInput(). What I achieve then is that, whenever the user loads a new CSV to the dashboard to be shown, the list of projects is updated accordingly, to be used as filters for the dashboard.
# We will then work with demo_rr(), calling the values associated to it:
demo_rr <- reactiveVal(NULL)
# To update demo_rr(), we can use a function like so:
observeEvent(input$risk_register_table, { #----
inFile <- input$risk_register_table
if (is.null(inFile)) {
demo_rr(NULL)
} else {
demo_rr <- as.data.table(read.csv2(inFile$datapath, header = TRUE))
# ... more processing happening here
# Update Projects List upon load:
updateSelectInput(session,
"project_filter",
label = "Project:",
choices = c("All", sort(unique(demo_rr$Project_Name))),
selected = "All")
demo_rr(demo_rr) # Not to be confusing: demo_rr() contains updated demo_rr object.
}
})
Talk about “closing the loop” 🙂
Making interactive graphs in Shiny
When you click in a GGPlot graph in Shiny, an few input variable values are generated. For this example, we will focus on input$plot1_click$x & input$plot1_click$x, where “plot1_click” is the name of a variable within the drawing code chunk for the plot on the left as shown here:

Now we actually created an OUTPUT in the UI section of the code for the graph to be included in the dashboard; we called the output “risk_plot1”, that we created in the SERVER part of the code as follows:
output$risk_plot1 <- renderPlot( #----
if(!is.null(demo_rr())) {
demo_plot <- ggplot(demo_rr(), aes(x = Probability, y = Impact, colour = Risk))
demo_plot <- demo_plot + geom_point(alpha = 0.3, size = 5)
demo_plot <- demo_plot + xlim(0.5, 3.5) + ylim(0.5, 3.5)
demo_plot <- demo_plot + scale_color_gradient(low="green", high="red")
demo_plot
}) #----
But we included the “click” variable to that plot in the UI part of the code:
plotOutput("risk_plot1",
height = "300px",
click = "plot1_click")
Now Shiny is able to retrieve the value of the X & Y positions of that click.
All we have to do is use the clicked position within the plot to locate the nearest Probability (x) and Impact (y).
We then are able to locate the row with the nearest pair, and fill the details part on the right hand-side with some of the corresponding details:
output$info <- renderText( #----
if(!is.null(demo_rr())) {
# Let's find the nearest point to the user's click position:
risk_selected <- which.min(abs(demo_rr()$Probability - input$plot1_click$x) +
abs(demo_rr()$Impact - input$plot1_click$y))
paste("Position clicked\nProb.:", input$plot1_click$x, "\nImp.:", input$plot1_click$y,
"\n\nRisk ID:", demo_rr()[risk_selected]$Risk_ID,
"\nRisk Name: ", demo_rr()[risk_selected]$Risk_Name,
"\n\nRisk Description:", demo_rr()[risk_selected]$Description,
"\nRisk Type: ", demo_rr()[risk_selected]$Risk_type,
"\n\nRisk Probability:", round(demo_rr()[risk_selected]$Probability, 0),
"\nRisk Impact:", round(demo_rr()[risk_selected]$Impact, 0),
"\nRisk Level:", demo_rr()[risk_selected]$Risk)
}
) #----
(Note: Initially, when you load the data, there will be no value for input$plot1_click$x… Thereby throwing a warning… One should control these things, but it’s beyond the point here 😉 .)
Keeping the list of all projects: <<- and Parent Environments
When you load a second (or third…) DIFFERENT CSV file of risks register with the correct format, say for another set of projects, the list of available projects needs to change.
You might have “played” and already filtered the dataset, using the “observeEvent()” trick explained earlier, thereby loosing track in the resulting dataset of originally available projects.
So you need to keep track of the original list of projects at all times.
To do so, I used a global variable (in “C lingo”):
From within a function, you can update the “Parent Environment” variable using the “<<-” assignation operator (an object).
What you do is define a variable in the main part of your script. You then can update its value using this operator. In our case, we keep the copy of the latest uploaded CSV when the user actually uploads it.
This way, we can use it later:
# To update demo_rr(), we can use a function like so:
observeEvent(input$risk_register_table, { #----
inFile <- input$risk_register_table
if (is.null(inFile)) {
demo_rr(NULL)
} else {
demo_rr <- as.data.table(read.csv2(inFile$datapath, header = TRUE))
# ... more processing happening here
# We keep a copy in the Parent environment for later use:
main_demo_rr <<- demo_rr
}
})
# ... More code
# To filter demo_rr(), we can use another function like so:
# When the user chooses a different project, we have to reload the original
# dataset with all projects, which we kept in "main_demo_rr"
observeEvent(input$project_filter, { #----
demo_rr <- main_demo_rr # We use the global copy of the variable
if(!is.null(demo_rr) & input$project_filter != "All") {
demo_rr <- demo_rr[Project_Name == input$project_filter]
} else {
demo_rr <- main_demo_rr
}
demo_rr(demo_rr) # Not to be confusing: demo_rr() contains updated demo_rr object.
}) #----
Enough! What about the results?
This has been a long and boring post about code… But what for?
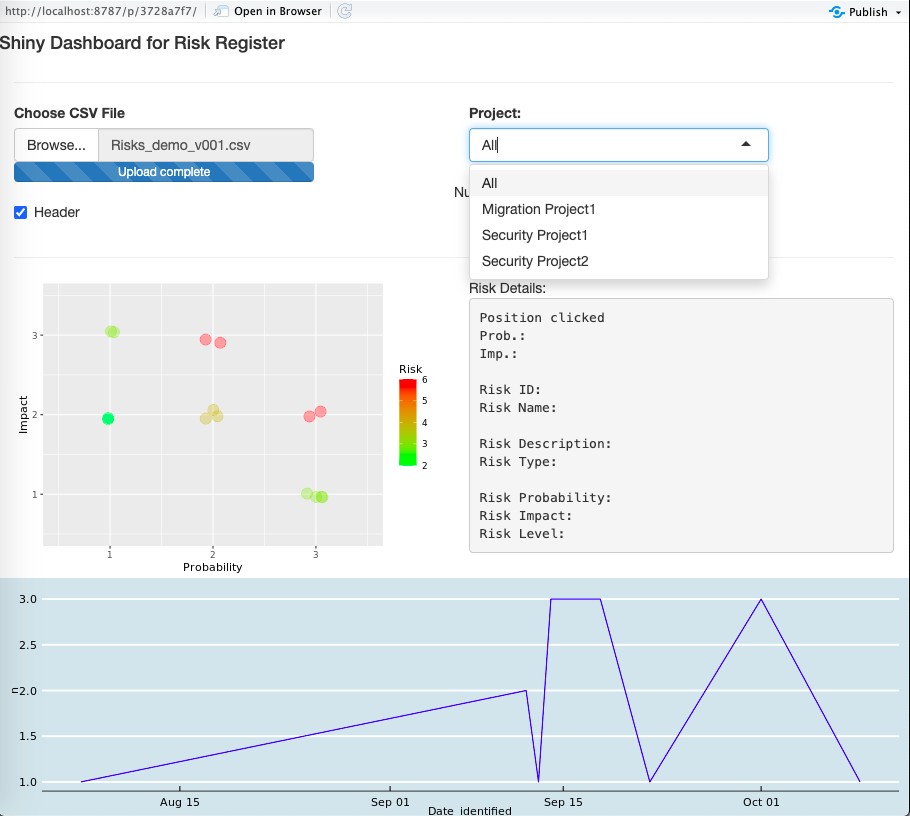
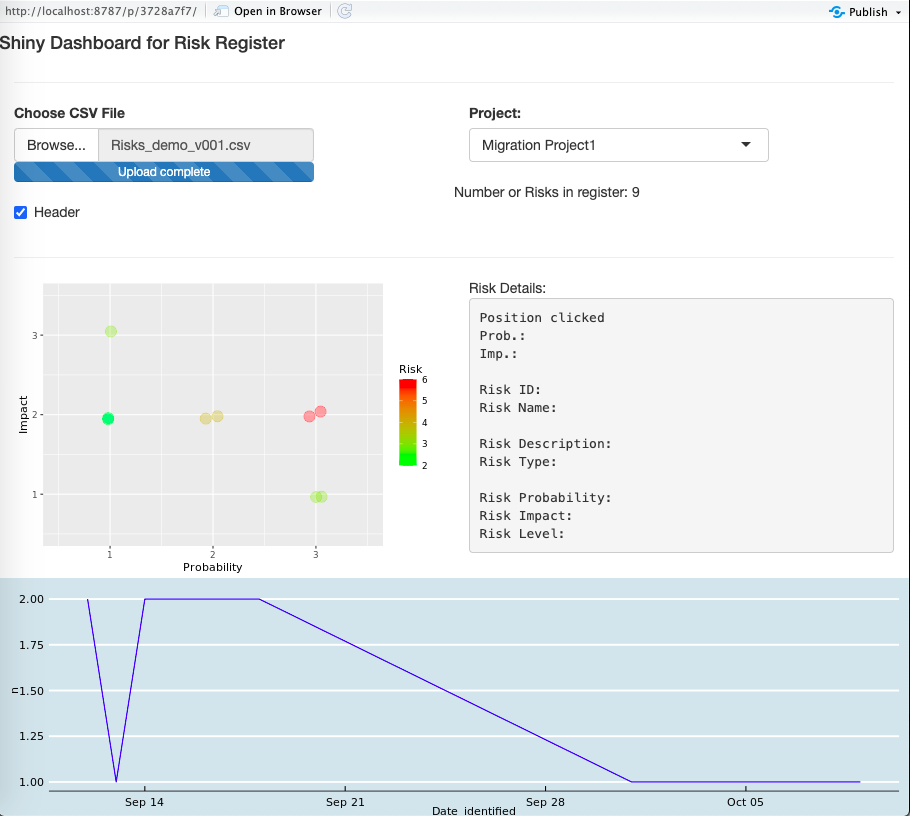
Well. The code available here allows you to launch a Shiny App that will take a correctly-formatted CSV (semicolon-separated values), to be loaded by a user (with the traditional “import” button), and present an interactive dashboard of the risks in the user’s list.
It offers a filter for the user to filter results shown below.
It presents the usual probability * impact risk plot, allowing you to click on any point and then presenting you with the contents of the (nearest) risk from where you clicked on the right.
At the bottom, a timeline of number of risks identified per date is shown too.
Both graphs are affected by the “projects” filter and updated accordingly.
Conclusions
We have moved from a difficult-to-interpret table of data (for the human eye, think hundreds of lines) to an interactive dashboard in Shiny.
As always, this is just a demo. Many more filters and graphs could be added, but I believe it shows a bit of the power of Shiny Apps.
And yes, you could do this probably easy with Tableau, Qlick, and even Excel. You can do it more complex with D3.js, why not.
I just use R, and some of its great libraries.
References
For Shiny options and (much) more documentation, just go here.
All the code used here is available on my GitHub account.