Intro
So I have been thinking a bit about chatbots and other NLP-related things lately. I’m probably NOT ready to implement an NLP-based Chatbot, that’s clear, but I can start doing some other things to get practice on the subject.
So this is going to be a multi-part thing, or rather a recurring subject in the upcoming weeks/months. I’ll try to take advantage of the summer to present and dive a bit into topics such as: Corpus, Stop-words, Tokenization, Stemming, algorithms such as TF-IDF (already introduced here for instance), and who knows what else.
The goal being to be able to understand things (and how they are implemented in R) a bit better maybe (nothing new under the Sun though). And I’ll try to do that through practical examples, some of which maybe will have to deal with logs, URLs classification (good or bad), and the likes. But let’s not get ahead of ourselves.
Start Simple: Webpage indexing
So I know this might seem like a stupid idea upfront: after all many websites have a so-called “sitemap”, whereby the contents are already somewhat indexed.
But I have had an issue recently, a very basic one: How to choose the tags and categories for my posts? Should I keep it to a minimum? Which ones are categories and which “tags”? Do my tags convey the actual contents of the different Blog entries?
Truth is, I only recently started thinking about this particular issue, while writing the last entry, and finding myself at a loss with the already existing (chosen by myself, mind you) categories and tags. And my site has around 40 entries in total by now (43 before the present one, to be exact).
Another reason for this idea of tags and categories is, I am now able to recommend my Blog (yes!) to some colleagues (not so much my friends, most don’t care about programming, R or IT Security). But although I know I have some contents on a specific topic, it takes me a bit of time to locate the entry I’m thinking of.
Both problems clearly are pointing at a particular need I have: I need help with the indexing of my contents so that it is easier for me to find it (and I don’t have Google JS code on the website, so I’m not really helping them here). This will probably fall in the category of “Topic Modelling”, actually.
I can think of two ways to go: to gather the data to analyze it: Basic crawling (once I know what I am looking for), or actually using the sitemap. As the first approach covers the concepts of the second, but in a harder way, I’ll do just the first one for now, encompassing in concept both.
Note: No entry next week (probably)
As it turns out, I will be away and will only be able to carry my job’s materials with me (I travel light, first time in a loooong time), so no server, no personal laptop, and it won’t be a vacation anyway…
Hence I think I’ll just skip the writing of code for a week, and instead spend some time brushing up on the concepts to be used when I actually start coding.
Nevertheless, let’s have a quick look at the first step…
Getting the data I’ll need: Quick glance at what’s ahead
So I really don’t have much time right now, but I wanted to open a new script and get started.
And so, for today I’ll just get the initial page, and locate the link for the next one. Of course later on I’ll need to repeat that, but for now that’s about OK.
# Crawl our website --An Appetizer:
library(dplyr)
library(curl)
library(xml2)
library(rvest) # for html_attr
# Select base page. Could have been the Home too on this Blog:
page_0_con <- curl("https://www.kaizen-r.com/category/blog/")
page_0 <- xml2::read_html(page_0_con)
I don’t know you, but I need some help to locate the right tags among all the mess. In Chrome & Firefox (and Edge, last time I checked) you can use the Developper tools (usually key: F12) of the browser and you’ll be able to click on your page, the browser will point you to the correct section of the HTML code:
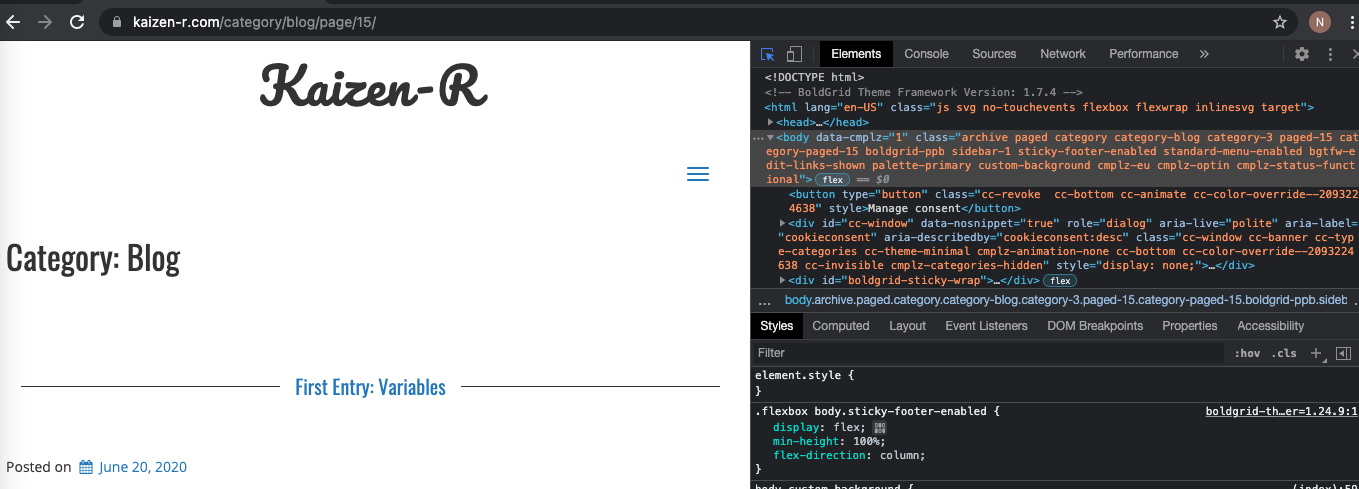
# Locate next page to crawl: F12 in your browser is your friend...
nav_next_div <- xml_find_all(page_0, ".//div[@class='nav-next']")
# Get the next URL out of the tags...
next_url <- nav_next_div %>% html_nodes("a") %>% html_attr("href")
But what would happen with a page that does not exist?
# spoiler - demo: we get a 404 after a few pages (as of today, that is)...
page_0_con <- curl("https://www.kaizen-r.com/category/blog/page/16/")
page_0 <- xml2::read_html(page_0_con)
Indeed, easy to check:
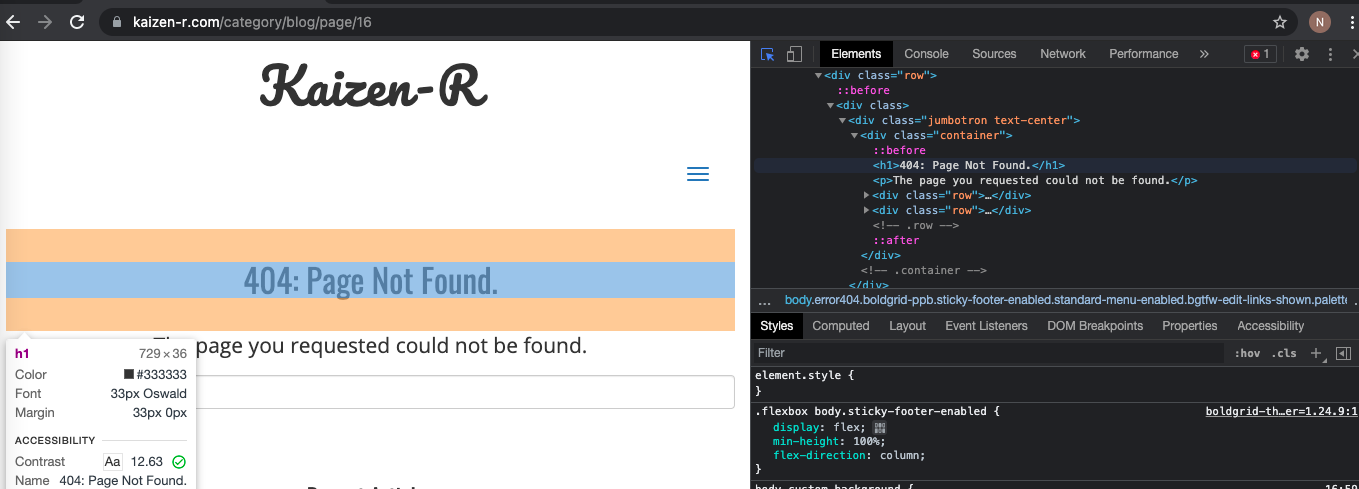
And we can get the contents from those pages we gather quite directly:
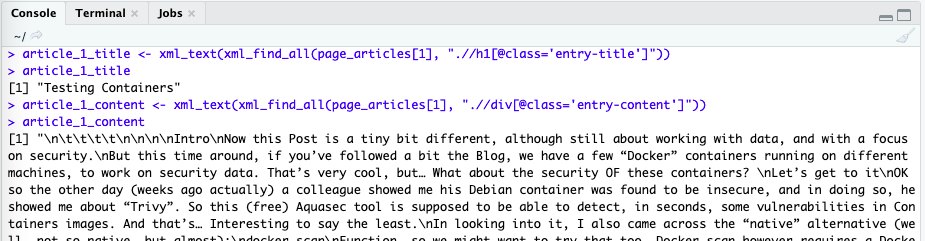
# While we're at it, let's get the contents of our first shown article: page_articles <- xml_find_all(page_0, ".//article") article_1_title <- xml_text(xml_find_all(page_articles[1], ".//h1[@class='entry-title']")) article_1_content <- xml_text(xml_find_all(page_articles[1], ".//div[@class='entry-content']"))
Conclusions
We’ll look at the text we’ll be gathering and we’ll see what we can do with it. Maybe I can program a helper that’ll be able to crawl my website’s articles, and recommend me automatically some tags and categories (and then, maybe not, it’s too early to say). We’ll see from there.
But first, I’ll be out reading. See you in a couple of weeks.