Intro
So I’ve been working on other things lately, but I wanted to keep improving/practicing a bit with the NLP concepts.
As I mentioned already, I spent a bit of my (little) spare time to review concepts. One book I am finding I rely heavily upon is “Mastering Text Mining with R”, from the Packt Editorial.
Today I choose to test some “Parts of Speech” tagging, using my own Blog as reference text.
Getting the text
So we already did that in past entries, which means I’ll skip it here and assume you get your text in a variable.
In our case, we ran the function “get_all_articles_kaizen_blog_vfuture()” from this code and ended up with all the blog entries in a dataframe called “all_articles_df_vfuture”.
all_articles_df_vfuture <- get_all_articles_kaizen_blog_vfuture()
The first article (the last one published) is now in the first row of that data frame, and its text, on which we focus today, is in the column “article_content”:
t_strings <- as.String(all_articles_df_vfuture$article_content[1])
So from now on, we’ll assume you have one text in a variable called t_strings, of type “String”.
First: Extract Sentences
You could think this is quite easy: Separate using the punctuation, and you can get sentences. Just look for the periods, right? Well apparently it’s not quite that easy.
So instead of trying our luck, we’ll use the openNLP package and some of its functions.
Let’s prepare a “sentence annotator”:
sent_annotator <- Maxent_Sent_Token_Annotator(language = "en", probs = TRUE, model = NULL)
And then let’s try and annotate our first article, using the NLP package’s function “annotate”:
# Now let's annotate the sentences in our latest article: annotated_sentences <- annotate(t_strings, sent_annotator) # And let's have a look: t_strings[annotated_sentences]
Good stuff. Indeed the choices these couple of lines of code have made differ a bit from what my personal approach would have done:

Me I’d have separated “Intro”, the first title, into a separate sentence. But then that “sentence” would have no verb, for instance…
Anyhow. So we have our article delimited in sentences.
Note: The “annotated_sentences” is an object of class “Annotation” that plays nice with objects of type String, as it turns out. Good to know. But let’s move on.
Getting words from sentences
Very similar to the above, we can get words out of our annotated sentences. (This is needed, though: you need annotated sentences to begin separating words).
(I’ve separated the first three sentences from the article for clarity):
# Let's first extract words, from annotated sentences. word_annotator <- Maxent_Word_Token_Annotator(language = "en", probs = TRUE, model = NULL) annotated_words <- annotate(t_strings, word_annotator, annotated_sentences) t_strings[annotated_words]
And we get indeed: First the sentences, then the separated “words”:

Good. Shall we continue?
Last step: Tagging Words
So far, these functions of separating sentences and words, we could probably have approximated using some regular expressions and “educated” if-then-else rules on strings.
But this last bit, to me, was a bit more of a challenge, theoretically speaking, and is an interesting thing: can we recognize “parts of speech” as in: verbs, nouns, articles…
Not straightforward, at least to me. Thankfully, the Apache-based openNLP package helps, once again:
pos_tag_annotator <- Maxent_POS_Tag_Annotator(language = "en", probs = TRUE, model = NULL) #pos_tag_annotator pos_tagged_sentences <- annotate(t_strings, pos_tag_annotator, annotated_words) head(pos_tagged_sentences, n = 30)
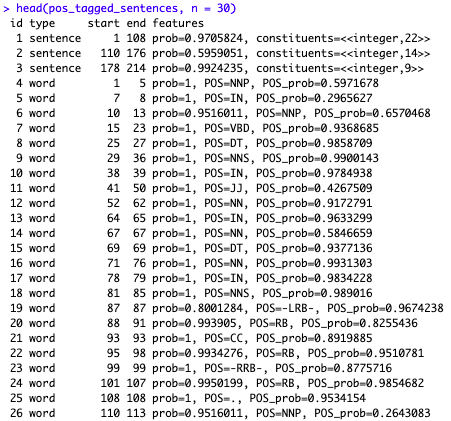
This is not quite as readable as one might want. We still see the sentences first, then the words, and now a “POS” tag appears but it’s encoded.
Let’s see if we can make it better. We will merge a simple data.frame that describes the tags better, with a data frame in which we map each word to their associated POS tag.
# Let's focus on the words only and for the first sentence only:
pos_tagged_words_sent1 <- pos_tagged_sentences %>%
subset(type == "word") %>%
subset(end <= 108) # 108 was the end of the first sentence, so it makes sense.
# Now we have all words limits for the first string:
sentence1[pos_tagged_words_sent1]
# Let's make it more readable now
# For reference: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
pos_simple_explainer <- data.frame(
tag = c("CC", "CD", "JJ", "NN", "NNS", "NNP", "VB", "VBD", "IN", "DT", "RB"),
desc = c("Coordinating Conjunction",
"Cardinal Number",
"Adjective",
"Noun, singular or mass",
"Noun, plural",
"Noun, proper",
"Verb, base form",
"Verb, past tense",
"Preposition or subordinating conjunction",
"Determiner", "Adverb")
)
word_types_vector <- sapply(pos_tagged_words_sent1$features, function(x) {
x$POS[[1]]
})
# Finally, let's have a look at the tagged POS:
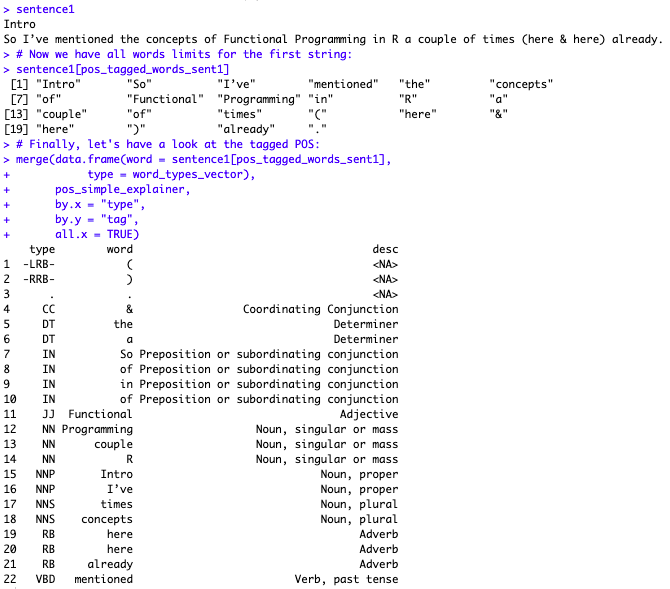
merge(data.frame(word = sentence1[pos_tagged_words_sent1],
type = word_types_vector),
pos_simple_explainer,
by.x = "type",
by.y = "tag",
all.x = TRUE)
The results are shown in the first screenshot of this entry.
Conclusions
We have used Apache’s openNLP libraries to work our way through:
- extracting sentences from a text
- extracting words from sentences
- tagging words to their corresponding type (or a reasonably good approximation, anyway), i.e. distinguishing verbs and articles and nouns…
Not bad!
I do recommend the book “Mastering Text Mining with R” if at all interested. This series of posts about NLP are in part inspired by that book, albeit adapted and applied in my own way and on my own text.